Historical Trends in R Package Structure and Interdependency on CRAN
Mark Padgham & Noam Ross
2026-06-29
Source:vignettes/pkgstats.Rmd
pkgstats.RmdIntroduction
The temporal development of software has been studied for many decades, commonly through the development of individual pieces of software or, in rarer cases, comparative studies between a select few pieces of software (see comprehensive literature reviews in Syeed et al. 2013; Chahal and Saini 2016). Software is dependent upon and shaped by developments in other packages or libraries. Any computer language has associated with it an evolving ecosystem of software packages and their interdependencies. The evolution of any one component of that ecosystem is best studied in the context of the evolution of the ecosystem as a whole.
One focal point of historically individual studies on software evolution has been the work of Lehman et al. (1997), who expressed their findings as a series of “laws” of software evolution. These “laws” include that, over time, software increases both in complexity and in functional content (or numbers of “modules”). Those laws of growth themselves derive from Turski (1996), who posited an empirically observed inverse-square law for software growth, later formalised in Turski (2002).
These “laws” of software evolution have strongly influenced the development of “Software Mining and Analytics” (Mens 2008). The field is focused on elucidating predictors of software quality. A useful overview was provided by Allamanis and Sutton (2013), who identified a number of research categories within this broad field, including one of “code statistics.”
For many computer languages, individual pieces of open-source software (“packages”) are held and distributed through centralized package distribution services (Ovens 2018) (“repositories”). These curated repositories of independently-contributed software exist for computer languages including python (Harihareswara 2018), LaTeX (“CTAN” 2021), JavaScript (Goldwater 2020), and many others (as well as operating-system specific repositories as described in Debian Policy Editors 2021).
Package repositories have collective properties that emerge from individual packages and their interdependencies (Decan, Mens, and Maelick Claes 2016). Decan et al. (2019) examined the evolution of dependency networks from seven package distribution systems, including the Comprehensive R Archive Network (CRAN). They observed that the Gini coefficient of inequality between dependent packages has increased over time in all systems. On CRAN, they found that both numbers of packages and numbers of dependencies have increased more slowly than for any of the other systems, as have numbers of package updates. They also observed that the “survival probability” (that a package is updated after some given time) has been far greater for CRAN than for other package ecosystems. This rate differed between packages with and without reverse dependencies.
There have also been detailed considerations of dependency networks from individual package distribution systems. Gonzalez-Barahona et al. (2009) showed progressive increases in Debian package inter-dependencies. They observed increases in the sizes of packages over time, and claimed that these reflected the laws of Lehman et al. (1997). They also observed that the relative sizes of packages, measured in terms of lines of code, remained relatively stable across releases. A recent analysis of the “pypi” (Python Package Index) package distribution system for python (Bommarito and Bommarito 2019) represented the most comprehensive analysis to that time of a single package distribution system for any computer language, drawn from almost two million releases of 179,000 packages.
The size of pypi necessarily restricted analyses to package metadata, although single metrics of package size were also included. Moreover, the size of pypi meant that analyses of dependency networks were also restricted to aggregate statistics only, with no analyses of the internal properties of dependency networks themselves. Thus while this represents an exemplary study of the evolution of a package distribution system, the size of this system precluded any analyses of how individual pieces of software evolve both internally, and in relation to the aggregate evolution of the system as a whole.
Compared with pypi, CRAN, the dominant repository of R packages, is more modest in size and more tractable for analysis in trends in development at both the individual and network level. Currently at ~140,000 releases of approximately 24,000 packages, it is about tenth the size of pypi. Studies of CRAN have to date largely considered package metadata such as DESCRIPTION files or personal networks of package authors. Plakidas et al. (2017) examined metadata from DESCRIPTION files, and found that the average R package has become more dependent on other packages over time, yet less likely to be depended on by other packages. They also revealed a high likelihood of authors of CRAN (and BioConductor) packages contributing code to other packages, although more recent developments have increased the dominance of single authors who do not contribute to other packages.
Other authors have examined relationships between CRAN and software development platforms such as GitHub (Decan et al. 2015; Decan, Mens, Maëlick Claes, et al. 2016), revealing GitHub to represent an “incubator” for early-stage code, and progression to CRAN happening once packages reach sufficient maturity. As a result, CRAN is relatively internally-stable, whereas GitHub packages depend on CRAN packages, yet not the other way around.
Analyses which have considered individual packages have also mostly examined aggregate data such as sizes of packages or dependency networks between packages. German et al. (2013) compared aggregate statistics of base, recommended, and contributed packages, and found contributed packages to grow in size at a faster rate that base or recommended packages, but for recommended packages to have far greater numbers of releases. Mora-Cantallops et al. (2020) examined metadata from DESCRIPTION files, and found the dependency network between packages to be generally “scale-free”, or dominated by a relatively small number of highly-connected packages. They also observed individual packages becoming increasingly dependent on other packages, yet less likely to be depended on.
The present work builds on this prior work, through drawing on
analyses of the entire contents of R packages, naturally including the
DESCRIPTION files, but all the contents of all code, documentation, and
testing directories. We begin by describing the the {pkgstats} R
package, which can be used to generate and analyse properties of R
package code, and the accompanying publicly-available database of code
statistics of all historical CRAN packages. We then describe trends in
CRAN package properties over the history of the archive, focussing on
trends in four areas: Package metadata (licenses, authorship,
translation), internal content and structure (file and function types
and sizes), intra-package code structure (function call networks), and
finally, dependency networks amongst packages. Finally, we discuss
implications and likely drivers of these trends, and potential further
applications and extensions of the {pkgstats}
package and database.
Methods
Fourteen years ago, in an article commemorating his “early history of the R project” ten years prior to that, Kurt Hornik called for
a considerable and concerted community effort … providing R packages to compute on R packages.
We developed the {pkgstats} package to quantify the structure and
content of R packages using static code analysis (Papamichail et al. 2016). The package includes
a function, pkgstats_from_archive(), which can be applied
to a local mirror of the CRAN archive to collate statistics from all
packages. {pkgstats} generates 95 variables quantifying and qualifying
package code. As the full process is computationally intensive, we have
published the data on all packages (current and previous versions) on
CRAN as of 22nd November 2022, and expect to update this resource
regularly. These data are available as the “pkgstats-CRAN-all” data set
at https://doi.org/10.5281/zenodo.7414296.
We studied R packages hosted on the CRAN including historical package
versions and archived (deprecated) packages. This includes the R
language itself, defined by a single “package” referred to as “base R”.
We include and distinguish between this “base” package, the suite of
default “recommended”
packages, and the overwhelming majority of “contributed” packages
(German et al. 2013). Our analysis ran on
a local mirror of CRAN as of 22nd November 2022, comprising 21,089
contributed packages, and 112,212 total package versions (for an average
of slightly under 5 releases per package). These analyses exist as a
reproducible repository at https://github.com/mpadge/pkgstats-analyses.
All results may be recreated by cloning the repository and typing
make.
In this paper we describe trends in the variables described in the four following subsections. {pkgstats} generates these as well as a larger superset of package-level statistics, the full list of which is in the online documentation.
Package metadata
Package-level metadata largely come from the Debian Control File (“DCF”) named “DESCRIPTION” (Hornik 2012), in all packages, which contains a subset of standard DCF fields. We extracted:
- Numbers of authors (as individuals with a specified role of “aut”);
- Numbers of contributors (as individuals with a specified role of “ctb”);
- Full entries of the “License” field specifying the type of license under which the software was released; and
- Entries in the “URL” field specifying one or more Uniform Resource Locators (URLs) for the package.
We also extracted a list of (human) languages provided in each R package for localization. R packages may include files used to translate all messages issued by code into other (human) languages. These files are placed in a dedicated /po sub-directory, with file names prefixed with standard prefixes (generally, but not necessarily, ISO 639-1 codes).
Lines of Code (LoC)
We quantified different types of source code from from R packages, using a custom C++ tool included in {pkgstats} This tool produces output similar to many common “Lines of Code” (LoC) analysis tools tools, plus addition information on white space and structure:
- Lines of code per (computer) language used in the package
- Lines of code, comment, and blank lines;
- Characters in code lines, along with numbers of white-space characters, to enable metrics of proportional white space; and
- Code indentation, including identification of tab-indentation.
These white-space and indentation metrics were developed to enable quantification of aspects of code outlay and design.
We measure these metrics across the following subsets of code. First, by function type:
- Exported functions intended to be called by users of a package; and
- Non-exported functions intended only to be called internally by other functions of a package.
And also by the sub-directories of R packages, which accord to the structure the structure defined in the “Writing R Extensions” Manual :
- The
/Rdirectory which holds all source files in the R language; - The
/srcdirectory which holds all code in other languages which needs to be compiled on package installation; - The
/instdirectory which generally holds bundles of external code, but may also include code used for cross-linking in compilation, including of other packages. Cross-linked code must be in an/inst/includesub-directory (as explained in this section of the “Writing R Extensions” Manual). All of the following analyses only consider the/inst/includedirectory, and all references to the/instdirectory imply this sub-directory only. Analyses excluded all other sub-directories within the/instdirectory. - The
/vignettesdirectory which includes extended documentation. (Such documentation may also be placed in an/inst/docfolder, but this was ignored here.) - The
/testsdirectory containing test files. - The
/datadirectory containing data files used to implement or demonstrate package functionality.
Static code analysis
We conducted static code analysis, identifying functions and objects in both R and compiled code in packages to characterize them at the function, package, and network level.
Static code analysis tools generally work by constructing parse trees which relate a grammar describing one or more computer languages to each expression encountered by tracing the code. An important first step is to “tag” each expression, identifying the kind of expression and its scope, implying its membership either of some component of the underlying grammar.
{pkgstats} incorporates two open-source libraries for code tagging and parse tree construction: “Universal ctags” (a fork of the unmaintained “ctags” library, Yamato 2022), and “gtags”, itself part of the GNU Global library (Tama Communications Corporation 2013). Using these jointly enabled us to parse both R and other languages used in packages, and construct a “call network” of functions between languages: “ctags” parses R code and “gtags” does not, but “gtags” parses more languages. We linked the results of two to provide complete coverage.
We used {pkgstats} to tag each expression in the R, src, and inst/include directories, providing the following data for each tagged item:
- The tag itself, such as the name of a function, variable, or other object;
- The name and path of the corresponding file;
- The full content of the expression in which that tag was used (as a text string);
- The kind of object (in R files, generally a function, functionVar or variable defined within a function, globalVar for global variables, or other objects defined by the R language; kinds of objects can be arbitrarily diverse in other languages);
- The computer language in which that object was referenced; and
- The start and end line numbers of the file in which that object is defined or referenced.
At the package, level we aggregated these values to produce:
- Numbers of internal and external functions in R.
- Numbers and kinds of objects in other languages.
- Lines-of-Code for each function or object definition in each language.
- References from each function (or object) made to all other functions (or objects), including references made to all functions defined in other base, recommended, or contributed R packages (see network analyses, below) .
We also parsed the R documentation (.Rd) files in each package using
the parse_Rd and Rd2txt functions of the
“recommended” {tools} package. From these we extracted the function in
an R package must have a corresponding documentation file in the number
of parameters for each function, and the number of documentation
characters for each parameter and the total length of documentation for
each function.
Network Analyses
We analyzed two networks within our extracted data: inter-package analyses of dependency networks between packages (akin to Decan et al. 2019), and intra-package analyses of the function call networks extracted from the “ctags” and “gtags” data described above.
Inter-Package Network Analyses
The ‘DESCRIPTION’ files of R packages must specify all external packages which a package imports. These data can be used to construct a dependency network between all packages, with packages (vertices) connected by their imports (edges). We derived the following value from the package network from package dependency networks, all of which were calculated with the {igraph} package (Csardi and Nepusz 2006).
- Numbers of packages which are not imported by any others (terminal vertices) in a dependency network;
- Average “in-degree” of network vertices, or average numbers of times each package is imported by others;
- Average betweenness centrality of each edge, which is the number of times that edge is traversed in connecting every package to every other package in the network;
- Network-level degree centrality, which is a measure of vertex degree standardised to the overall size and structure of the network (Freeman 1978).
- A measure of the overall “size” of the network as the average distance between all pairs of vertices.
Betweenness centrality provides insight into how centralised the network is, with higher values reflecting networks in which connections frequently traverse a common, central region. The network-level degree centrality reflects the extent to which vertices all have a relatively high in-degree; networks in which all networks have an equal in-degree have no effective centre, and so have a degree centrality of zero. In contrast, networks with a few highly-connected central vertices and many vertices with low in-degree will have a high degree centrality. These two centrality metrics provide slightly different insights: betweenness centrality will increase to the extent to which a network manifests a single, common centre; degree centrality will increase to the extent that networks become more centralised in general, regardless of whether or not any singly identifiable centre forms.
Networks with low degree centrality are readily traversable, and so will generally have lower average distances between all pairs of vertices. The distance metric offer additional insight. It will, for example, be higher independent of degree centrality for networks with extended peripheral connections. Finally, we note that clusters or local network communities were not considered here, as the dependency networks of CRAN packages are almost always so highly connected that the largest connected cluster represents over 99% of the network.
Intra-Package Network Analyses
We used the references generated by the static code tagging to
construct an “function call network”, of all references in R function to
other functions within the packages and to their dependencies, including
base and recommended packages, and contributed packages imported.
Functions were attributed to packages by matching function names.
Function names in R do not have to be unique, and “namespace conflicts”
may arise between packages implementing different functions with the
same name. We presumed that namespace conflicts most commonly arise in
re-definitions of functions initially defined in base or recommended
packages, and in all such cases we attributed a function to the external
or contributed package over definitions in the base or recommended
packages. Intra-package networks also included code in other languages
included in /src directories.
Function call networks within individual packages are commonly structured in several distinct clusters, and thus numbers of clusters provided an important first metric for intra-package analyses. Intra-package analyses considered the following metrics:
- Ratio of numbers of edges to numbers of vertices.
- Numbers of distinct clusters between all functions or objects across all languages.
- The betweenness centrality of the function call network.
- Numbers of terminal vertices (functions which do not call any other functions).
- The average vertex degree.
Coupling Instability
Coupling Instability is an important concept in the analysis of software dependency networks (Martin 2003), and depends in turn on numbers of so-called afferent and efferent couplings. For any given package, these are defined as:
- Afferent Couplings: numbers of functions in other packages which depend on functions within the package.
- Efferent Couplings: numbers of functions from other packages which the package depends on.
In other words, afferent couplings are numbers of inbound edges from all other packages to a given package, while efferent couplings are outbound edges coupling that package with all other packages.
Respectively denoting afferent and efferent couplings by and , the coupling instability, , is defined as . Packages which depend on many external calls (high efferent couplings), yet upon which few other packages depend (low afferent couplings) thus have a high coupling instability, while packages upon which many other packages depend, yet which themselves depend on few other packages have a low coupling instability. The analyses below quantified coupling instability for each package from the dependency networks, using total numbers of function calls between all packages, in order to estimate the average coupling instability of the entire network.
We also adapted this measure of coupling instability between packages to a measure of internal coupling instability (Almugrin and Melton 2015) between the individual files of one package. Packages with high internal coupling instability make many calls between individual files, while packages with low internal instability make more calls within single files, and relatively fewer between them.
Temporal Trends
We report descriptive statistics of change in the above measures of CRAN software over time, focusing on two types of change: developments across all packages on CRAN simultaneously, and developments for individual packages over sequences of releases.
We summarize all-CRAN developments using two measures: annual values and snapshots. Annual values are comprised of values of packages uploaded or updated in a specific year, disregarding packages uploaded in previous years and not yet updated. Snapshots represent values of all packages on CRAN at the end of a given year, regardless of how long ago a package may previously have been updated. In general, trends in snapshots are smoother than annual values. In figures below, solid lines represent annual values and dashed lines represent snapshots unless otherwise indicated. As most values calculated were log-distributed, we report trends in geometric mean values ().
Under the plausible assumption that rates of package updates follow some kind of Poisson-like process, the ages of packages at any given time will be exponentially distributed, analogous to distributions of waiting times for Poisson processes. This means that values derived using CRAN snapshots will generally reflect exponentially-smoothed versions of annual values. Many of the graphical results which follow depict results derived using both of these approaches, in which:
- solid lines represent annual values, which are generally noisier versions of
- dashed lines, which represent effectively exponentially-smoothed versions of the same data using CRAN snapshots for each year.
Where no additional interpretations are given, solid lines in all of the results that follow represent annual values, while dashed lines represent results derived from CRAN shapshots. See Fig. 1A immediately below, for an example. Where also not otherwise mentioned, all reported values refer to (generally noisier) annual values, and not to values derived from (generally smoother) CRAN snapshots.
Results
Annual submissions
Numbers of annual submissions increased progressively until the 2020 pandemic (Fig. 1A), during and after which they remained relatively flat. Total submissions to CRAN have always been strongly dominated by resubmissions. New submissions have generally represented well under 20% of all submissions, with an increase above this ratio between 2015–2017, peaking at 22% during 2016.
Increases for the current year of 2026 reflect new submissions comprising just under 20% of total submissions, still below the proportion reached in 2016. The trajectories for the most recent years of Figure 1A suggest at most a marginal increase in trajectories prior to 2020.
Metadata
Numbers of both authors and contributors have increased over time (Fig. 1B), with contributors having been rarely acknowledged at all prior to 2010. Acknowledgement of contributions increased soon after then to an average of just under one acknowledged contributor per package in 2022. Although recent increases in numbers of both authors and contributors have been broadly linear, both show more recent signs of slowing down.
Diversity of license declarations increased up to around 2007 (Fig. 1D), followed by a pronounced drop and progression into a roughly stable range of somewhere over 50 distinct entries. Numbers of unique licenses primarily reflect numbers of ways of declaring licenses, rather than numbers of actual licenses (for example, “GPL >= 2.0” is different to “Any GPL license version 2 or higher”, although both clearly refer to the same license). The different ways of specifying the three versions of GPL licenses have accounted for over 83% of all CRAN packages, with the second most common type license being MIT, at 9.6%, followed by BSD at 2.0%. One of these three classes of licenses are used in 95% of all CRAN packages.
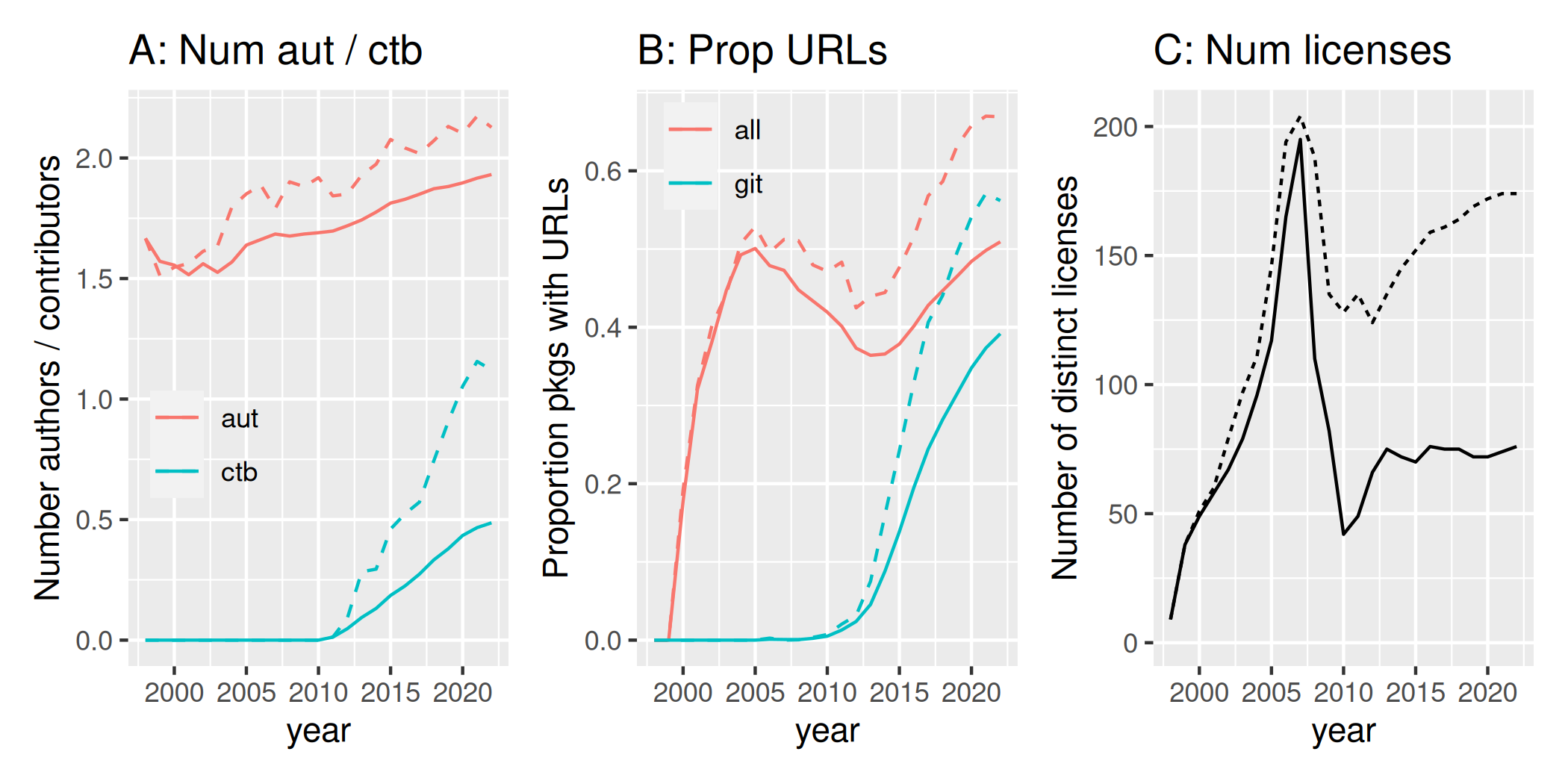
The practice of translating messages within R packages into other
languages has steadily declined in recent years (Fig. 2A), suggesting a
pronounced increase in acceptance over the last 15 or so years of
English as a globally standard language, and a concomitant decrease in
active acknowledgement of other languages. (The en@quot
translation entry only translates between different quotation styles
and encodings.) Rates of decrease since 2008 equate to 1.5% fewer
packages per year including translations, from a total of just over 20%
of all packages in 2008, to barely over 1% in 2021. Rates of decrease
have nevertheless slowed somewhat in recent years, and the use of
translations appears to be on the rise again since 2021, perhaps
reflecting the publication of the {potools}
package to facilitate transitions in R packages.
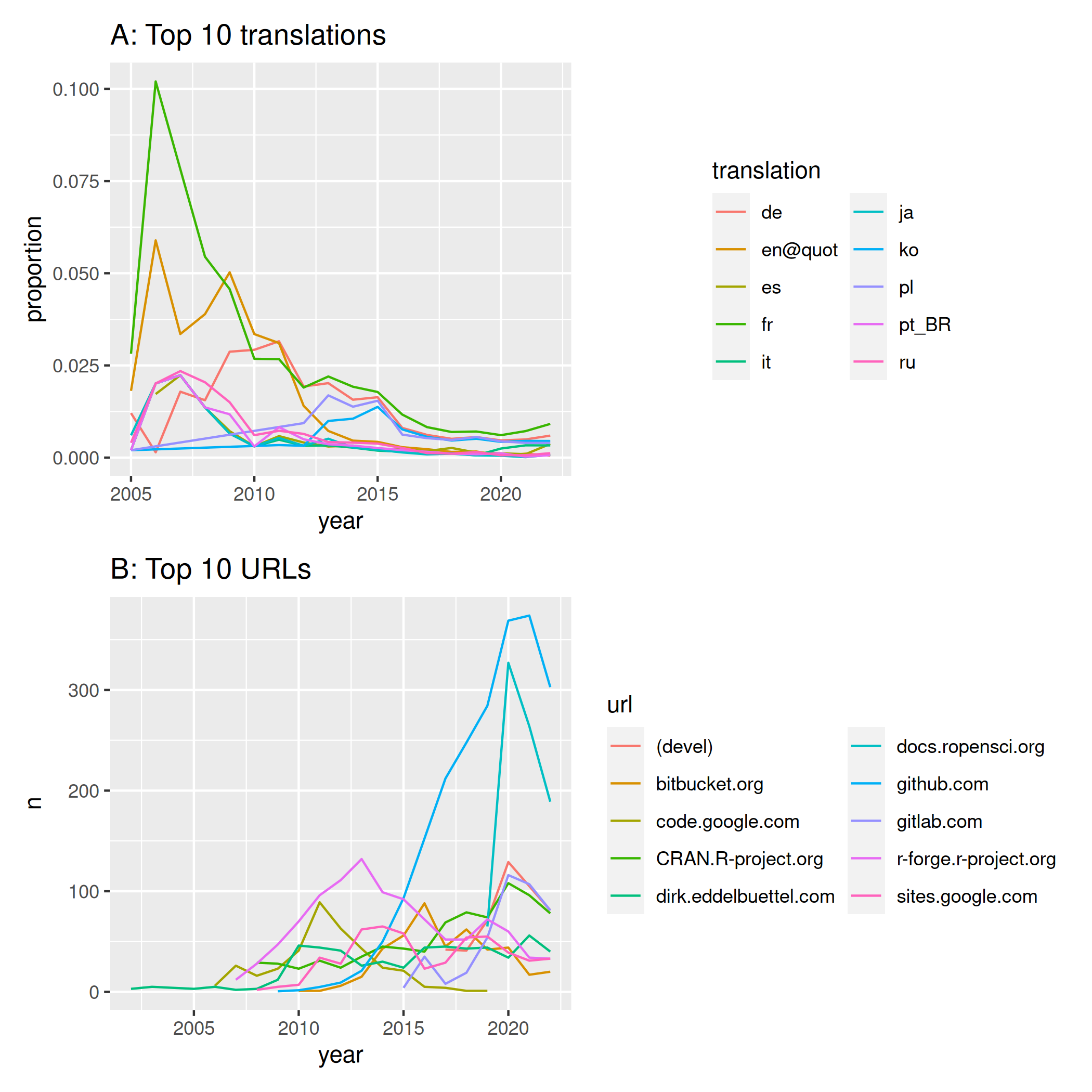
The top domains of URLs provided in package ‘DESCRIPTION’ files show
the rise and fall of different online homes for development, secondary
hosting and documentation of CRAN packages. r-forge reached a peak of
popularity in 2013. A variety on online code repositories began to be
linked to around 2010, with GitHub clearly dominating since around 2016.
The other domain that clearly stands out is ropensci.org,
followed by two other notable domains of gitlab.com and
dirk.eddelbuettel.com.
Package Structure and Content
The temporal development of numbers of files manifest several notable
characteristics (Figure 3). Unsurprisingly, R packages have always been
dominated by files in the R/ directory, numbers of which
increased considerably up to around 2010, after which they have broadly
stabilised at mean values of around 13-15 files per package (Fig. 3A).
The /vignettes directory is the only place within R
packages in which numbers of files have remained relatively constant
over the preceding 25+ years. Numbers of files in both
/inst and /data directories decresed
dramatically over CRAN’s first decade, and are still slightly decreasing
even now. Numbers of files in /src directories have varied
only slightly around typical values of 6-8, while numbers of files in
/tests have consistently increased to the recent status of
having the second greatest number of files other than the
/R directory itself.
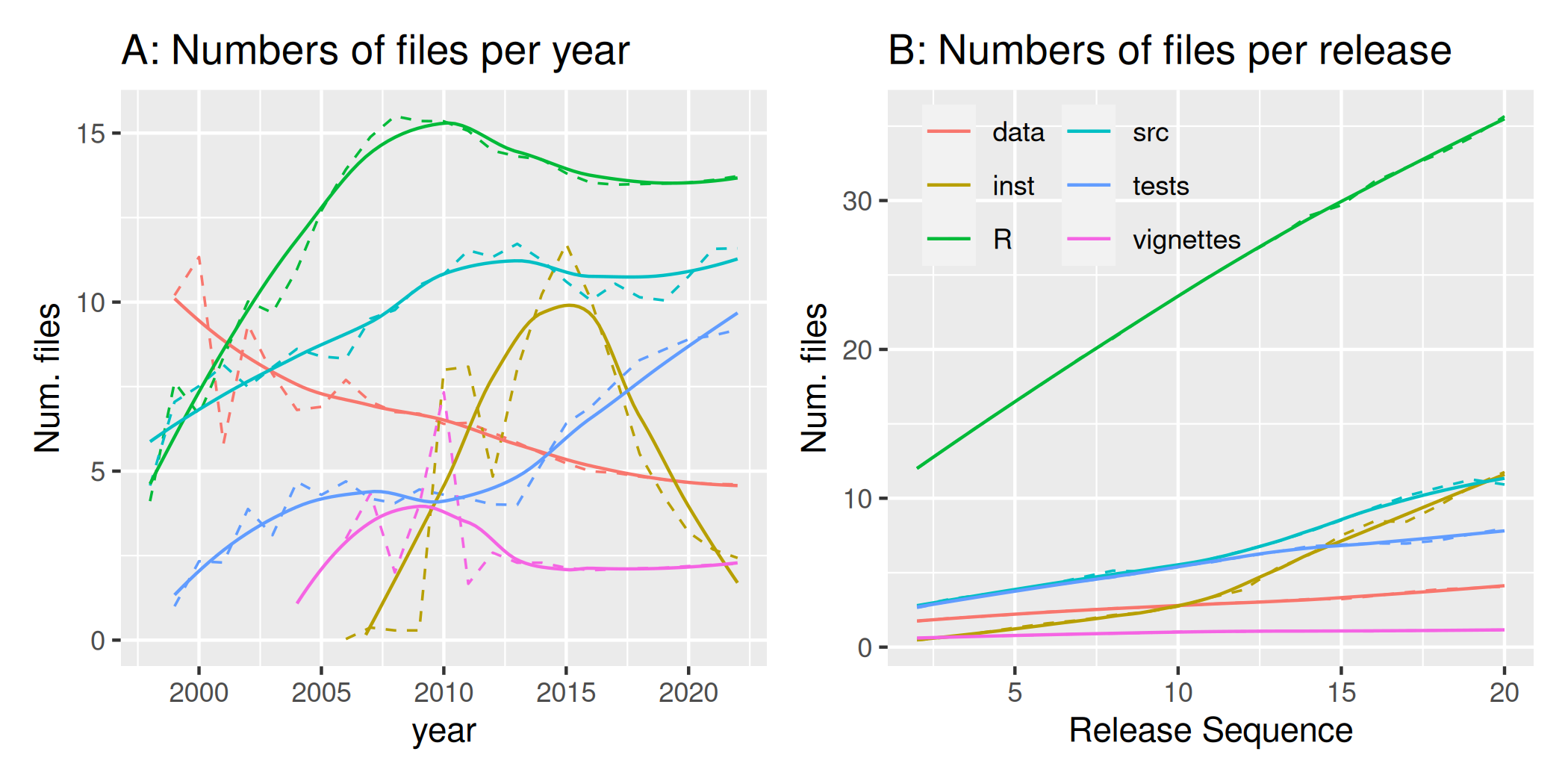
Figure 3B shows equivalent changes within individual
packages across successive releases. Numbers of files generally
progressively increase as packages mature, with especially pronounced
increases in the /R and /tests/ directories,
and to a lesser extent /inst, and /src
directories. These changes in /src and /inst
directories in the later phases of package maturation may reflect
restructuring code from the /src to the /inst
directories in order to allow cross-compilation by other packages.
Numbers of test files generally increase progressively through package
maturation. The only directory in which numbers of files do not notably
increase as packages mature is /vignettes.
Code Metrics
Annual Developments
Figure 4 shows the temporal evolution of a number of code metrics.
Lines of Code (“LoC”) in the primary /R and
/src sub-directories increased between 2000 and 2005, after
which time LoC in these directories have slightly decreased, converging
to just a geometric mean of just under 1,000 lines in both
/R and /src directories (Fig. 4A). LoC per
function (Fig. 4B) decreased from very high values in the early CRAN
years to stabilize from 2005-2020. The slight decreases discernible
since around 2015 amount to one LoC less for exported, non-exported, and
/src functions every 3.4, 8.5, and 1.5 years, respectively,
a trend that has nevertheless reversed in the most recent two years.
Total numbers of R functions per package initially increased until
around 2007, peaking at just under 30 exported and over 60 non-exported
functions (Fig. 4C). Numbers of exported R functions decreased since
then to around 15 exported and 25 non-exported functions shortly after
2015, before having since increased again to current respective values
of around 20 and 35. Numbers of functions defined in /src
directories have followed broadly similar trajectories to exported /R
functions. Numbers of functions per source file in both /R and /src
directories have nevertheless generally progressively decreased since
the early 2000’s to now amount to less than four /R functions and just
over five /src functions per file (Fig. 4D), with slight increases once
again discernible since around 2017.
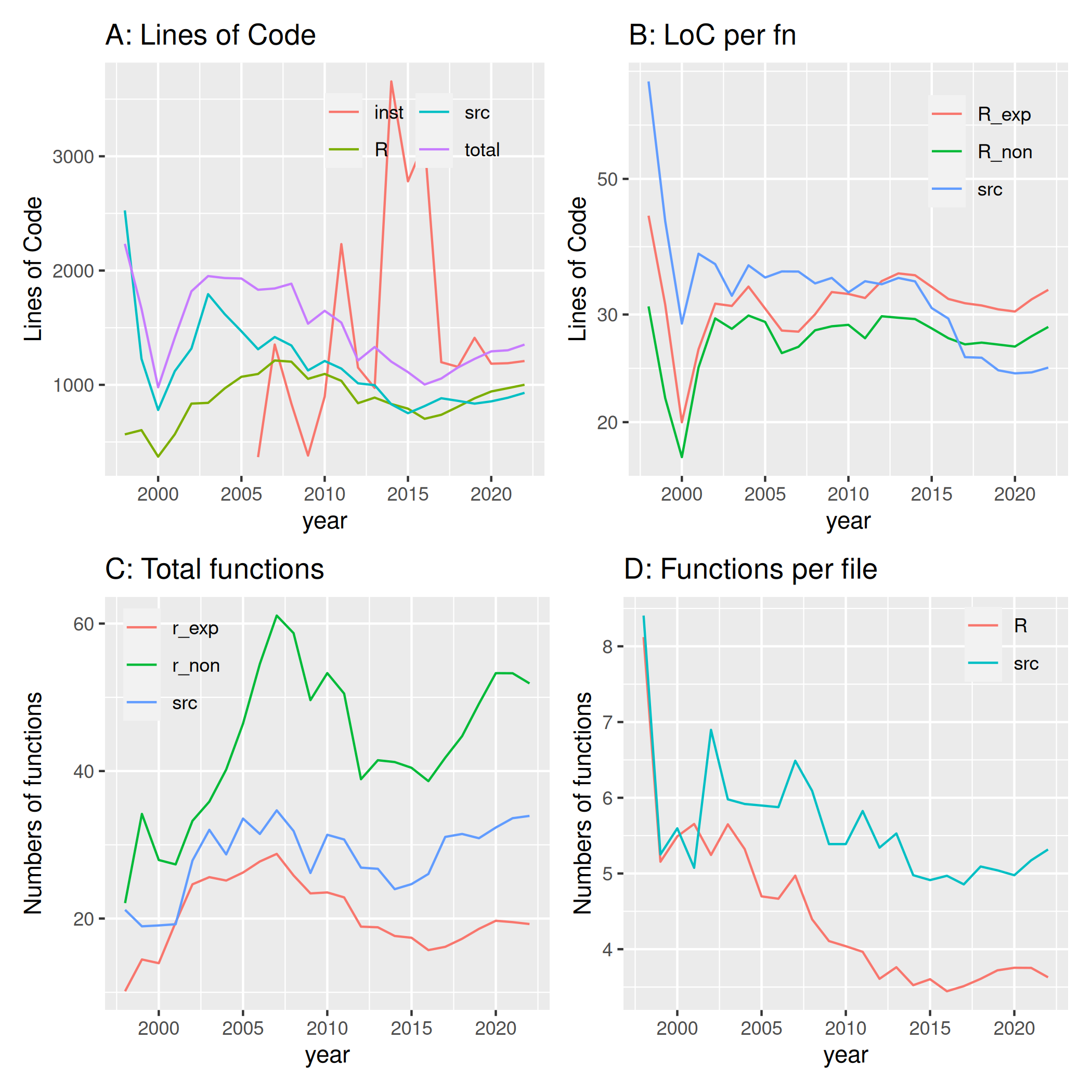
Sequential Releases
Figure 5 shows results equivalent to Fig. 4, but for the development
of the respective metrics with each sequential release of a package,
rather than annual developments. Lines of code generally increase as
packages mature, with mean numbers of lines in the /R directory
increasing tenfold from under 400 for first releases to over 5,000 once
packages mature beyond a 50th release. Beyond the first few releases,
there are always fewer LoC in /src directories than in
/R directories. This contrasts with the annual aggregate
results of Fig. 4A, which suggest more LoC in /src than
/R directories until sometime after 2010, and roughly equal
numbers since then. This difference reflects the fact that most packages
have only one or two releases (the distribution of numbers of releases
is not shown here, but manifests a very smooth exponential decrease), so
Fig. 4A is dominated by packages in a very early state of development,
for which LoC in /src often exceed numbers in
/R. Similar to patterns for /src and
/inst directories in Fig. 3B, decreases in LoC in
/src directories in the later phases of package maturation
may reflect restructuring code to /inst directories. This
clear peak in LoC in /src directories may in turn suggest
this is an approximate number of releases before other developers become
aware of the functionality of package /src directories. The
clearest result of Fig. 4A is manifest in total LoC, which increases in
a linear manner even out to the 100th release of a package.
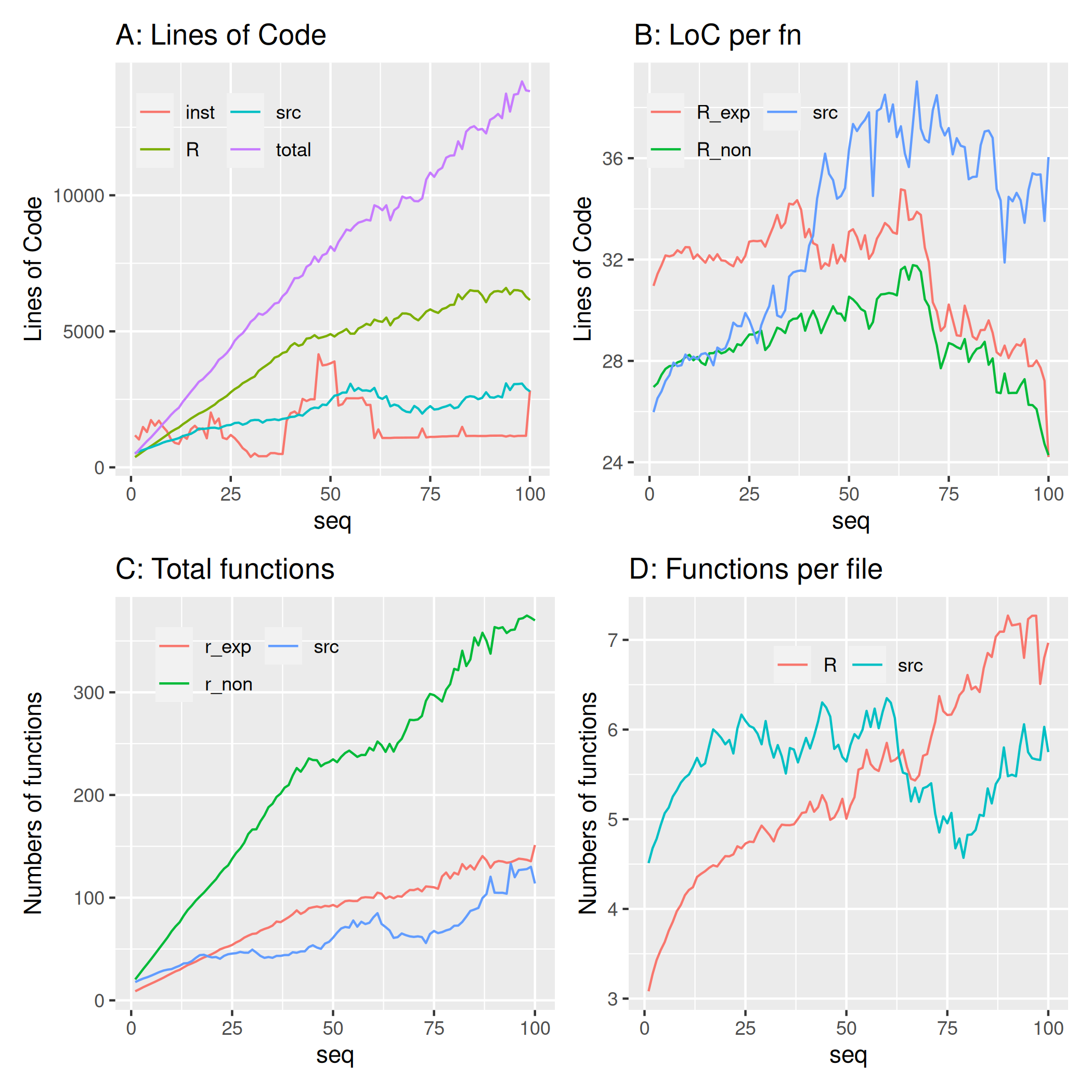
These increases in LoC nevertheless corresponded to general decreases
in LoC per function with increasing numbers of releases (Fig. 5B). In
all directories, LoC per function either slightly increased or remained
generally stable over the first 50 or so releases, beyond which
functions in all directories clearly become considerably more
streamlined, with LoC decreasing markedly out to the 100th release.
Measures of LoC per function manifest broad peaks in all directories
after around 70 or so releases, after which they all decreased, and more
so for /R than for /src functions. The
decreases in the latter portions of Fig. 5B are equivalent to removing
one LoC per function for around every 9 releases.
The increasing total measures of LoC of panel A combined with
decreasing LoC per function of the latter part of panel B suggests that
more functions are added as packages mature, which is precisely what
Fig. 5C reveals. Packages initially contain less than ten exported
functions on average, yet this increases over 10-fold to around 150 by
the 100th release. Numbers of /src and exported
/R functions follow broadly similar trajectories,
increasing from under 20 functions, to well over 100 by the time of the
100th release. Numbers of non-exported /R functions
manifest the most pronounced increase, of over 15 times from 20
functions for initial releases, to well over 300 for the 100th release.
Finally, numbers of functions per file show no clear trend for src code,
remaining broadly stable at around 5-6 functions per file (Fig. 4D). In
contrast, /R code files begin with 3-4 functions per file,
and increase progressively to around eight functions per file after 100
releases, in the context of Figs. 4B-C clearly mostly due to breaking
large non-exported functions down into multiple, smaller functions.
Numbers of functions depicted in Fig. 4C actually count any arbitrary
code objects in all languages contained in /src
directories, and so corresponds directly to the “modules” posited to
increase according to the inverse-square “law” of software evolution
(Turski 1996, 2002; Lehman et al. 1997).
The defining qualitative feature of such inverse–square growth is an
initially highly concave form, with rates decreasing notably as packages
mature. The trajectories of Fig. 4C appear in contrast strikingly
linear, all manifesting trajectories which would be very poorly
described by such an inverse-square form.
Package Imports and Exports
Like the “standard” libraries for the python language, R has a core set of “base” and “recommended” packages. The function call networks extracted by pkgstats enable counting numbers of calls to each of these groups of packages, as well as to “contributed” packages hosted on CRAN.
Annual Developments
Figure 6A shows the change over time in proportions of calls to these three groups of packages, revealing a recent tendency (since around 2015) of fewer calls to base R functions, from over 80% of all function calls in the early 2000s, to below 70% in the previous two years. This decrease has been offset by greater numbers of calls to functions in contributed packages, while calls to recommended packages have remained generally stable at around 20%. Although calls to contributed packages have always represented the lowest proportion of these three groups, this recent increase nevertheless places them on almost equal proportion (at 12%) to calls to recommended packages (at 18%).
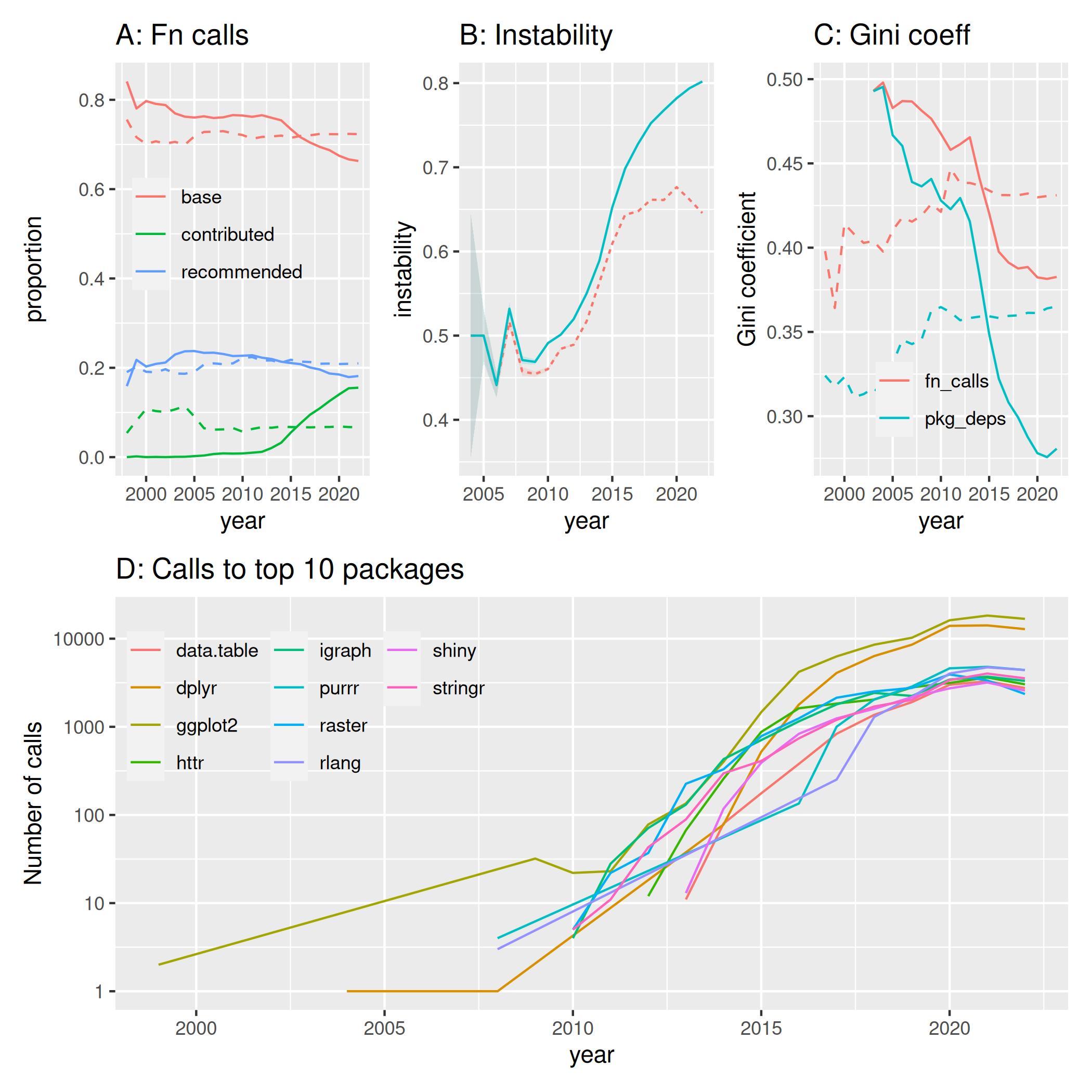
Figure 6B shows the “coupling instability” of packages over time. As explained above, this is a measure of the extent to which packages depend on external functionality (efferent couplings) without other packages in turn depending on them (afferent couplings). Packages on CRAN were largely stable until around 2010, at a coupling instability of around 0.5, meaning numbers of functions from each package which were imported by other packages were roughly equal to numbers of external functions each package imported. Instability has increased markedly since that time, indicating that packages have become increasingly dependent on external functionality, while the average package is less likely to provide functionality used by other packages. The coupling instability over the preceding two years of around 80% implies that packages make on average eight calls to other packages for every two calls made to that package.
As another aggregate measure of changes in package imports, Decan et al. (2019) analysed Gini coefficients, which are standardised aggregate differences in numbers of imports between packages. Systems in which all packages import equal numbers of dependencies have a Gini coefficient of zero, while systems with maximally heterogeneous numbers of imports have a Gini coefficient of one. While they concluded that Gini coefficients have increased over time for all seven of the package distribution systems they studied (including CRAN), at least over their time period of 2012-2017, our equivalent results are depicted in Fig. 6C, revealing a difference on how annual values are defined and calculated. Using “annual values” through aggregating statistics only from packages uploaded in each year (solid lines) yields Gini coefficients which decrease over time, while calculating annual values as “CRAN snapshots” as the entire system would have existed for each year (dashed lines) yields Gini coefficients which increase over time. Decan et al. (2019)’s results appear to qualitative accord with our “CRAN snapshot” values for package dependency networks.
Moreover, that panel depicts Gini coefficients calculated both from numbers of imported packages, and total numbers of external function calls are qualitatively similar, though differing in scale.
Finally, figure 6D depicts changes in numbers of unique function calls from each package to the top ten contributed packages, defined as the ten packages with the largest total number of unique function calls from all packages throughout the history of CRAN. The top two packages of {ggplot2} and {dplyr} account for 15.2% of all function calls from all contributed packages over the time shown. Numbers of function calls are shown on a logarithmic scale, with numbers of calls to each of these packages increasing exponentially, before more recently levelling off or even slightly decreasing.
Sequential Releases
The first two panels of Figure 7 show results equivalent to Figs 6A-B, but for changes with progressive releases of each package. Packages tend to make progressively fewer calls to base R functions as they mature, although this decrease is relatively less pronounced than the overall decrease over time of Fig. 6A. In contrast changes to all packages over time, decreases in calls to base R functions as packages mature are offset by relative increases to calls to recommended packages. Calls to contributed packages actually decrease as packages mature. Such changes become relatively less pronounced over successive releases, stabilising after around 50 releases at around 75% of all function calls to base R, and just under 25% to contributed packages.
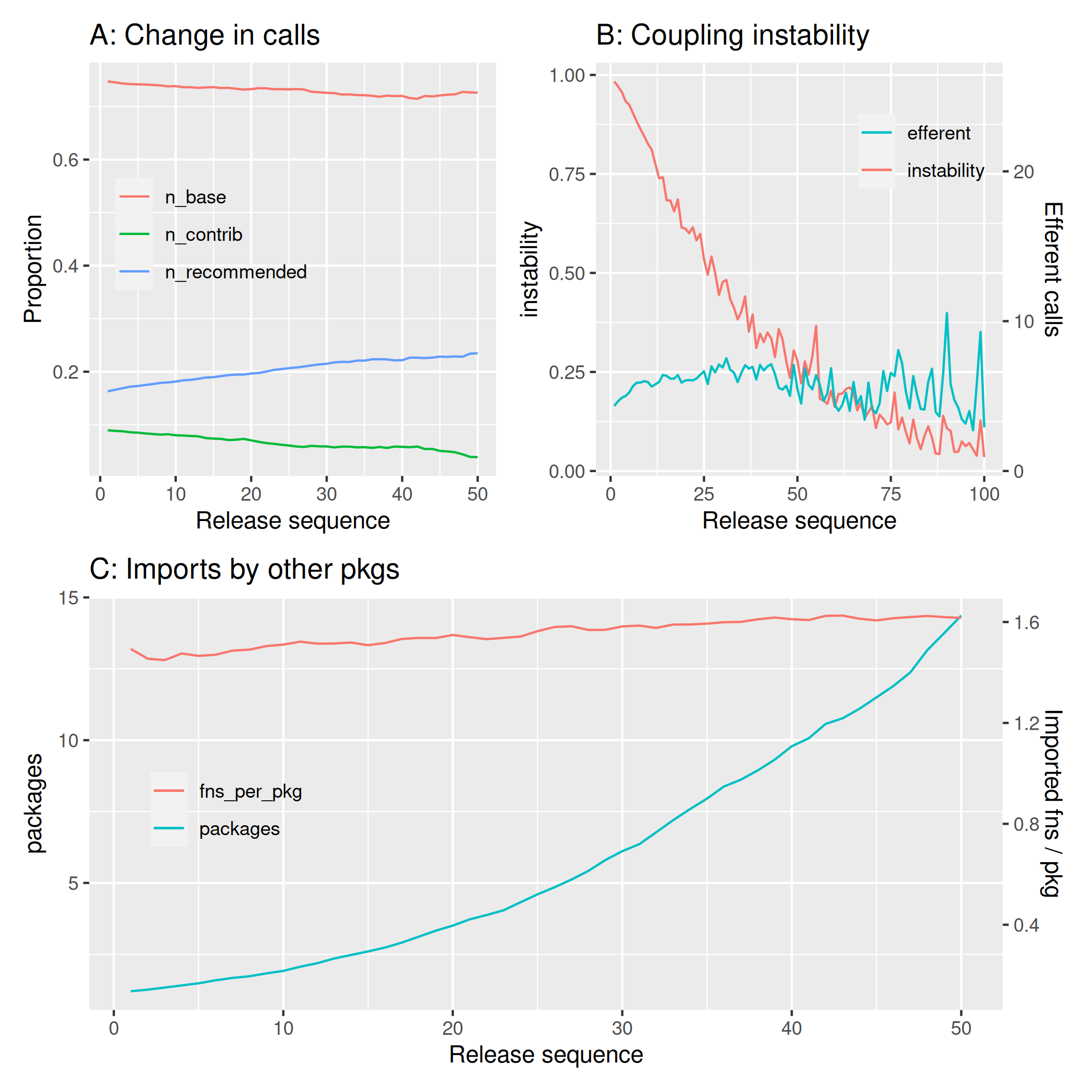
Figure 7B shows the average trajectory of coupling instability for individual packages across the depicted numbers of sequential releases, which decreases as packages mature. This would be expected if packages are increasingly likely to be imported by other packages. Average numbers of efferent couplings (numbers of outward calls from each package to other packages) stay largely stable as packages develop. Increases in package stability arise as packages develop purely through being imported as dependencies by increasing numbers of other packages. This suggests that the best way to counteract the increasing coupling instability of CRAN as a whole depicted in Fig. 6B would be to ensure that packages remain progressively developed, rather than abandoned (or archived) after only a few releases.
Finally, Fig. 7C shows progressions of both packages and individual functions being imported into other packages as a function of release sequence. The number of packages importing a package increases progressively with numbers of releases. Packages with less than ten releases are, on average, imported by very few other packages, while packages with 40 or more releases are imported by ten other packages on average. Packages import on average only 1-2 functions from any given package, and numbers of functions imported by other packages increase only marginally as packages mature.
The slight increase in numbers of functions imported by other packages nevertheless suggests a relationship between total numbers of functions exported by a package (Fig. 5C), and numbers imported by other packages. Taking only the latest versions of all packages and relating these two values reveals that other packages are likely to import one additional function on average for every 2.8 additional functions exported by a package.
Network Analyses
Annual Developments
The first two panels of Fig. 8 show the temporal development of the CRAN package dependency network. Most network metrics have broadly stabilised over the preceding five or so years, with variations much more pronounced prior to 2015. The proportion of terminal vertices, or packages not imported by any other packages, has remained broadly stable at around 55-60% of all packages. The mean vertex degree of the dependency network has nevertheless progressively increased, especially since around 2012, indicating that those packages which are imported by others have been imported by increasing numbers of other packages (Fig. 8A).
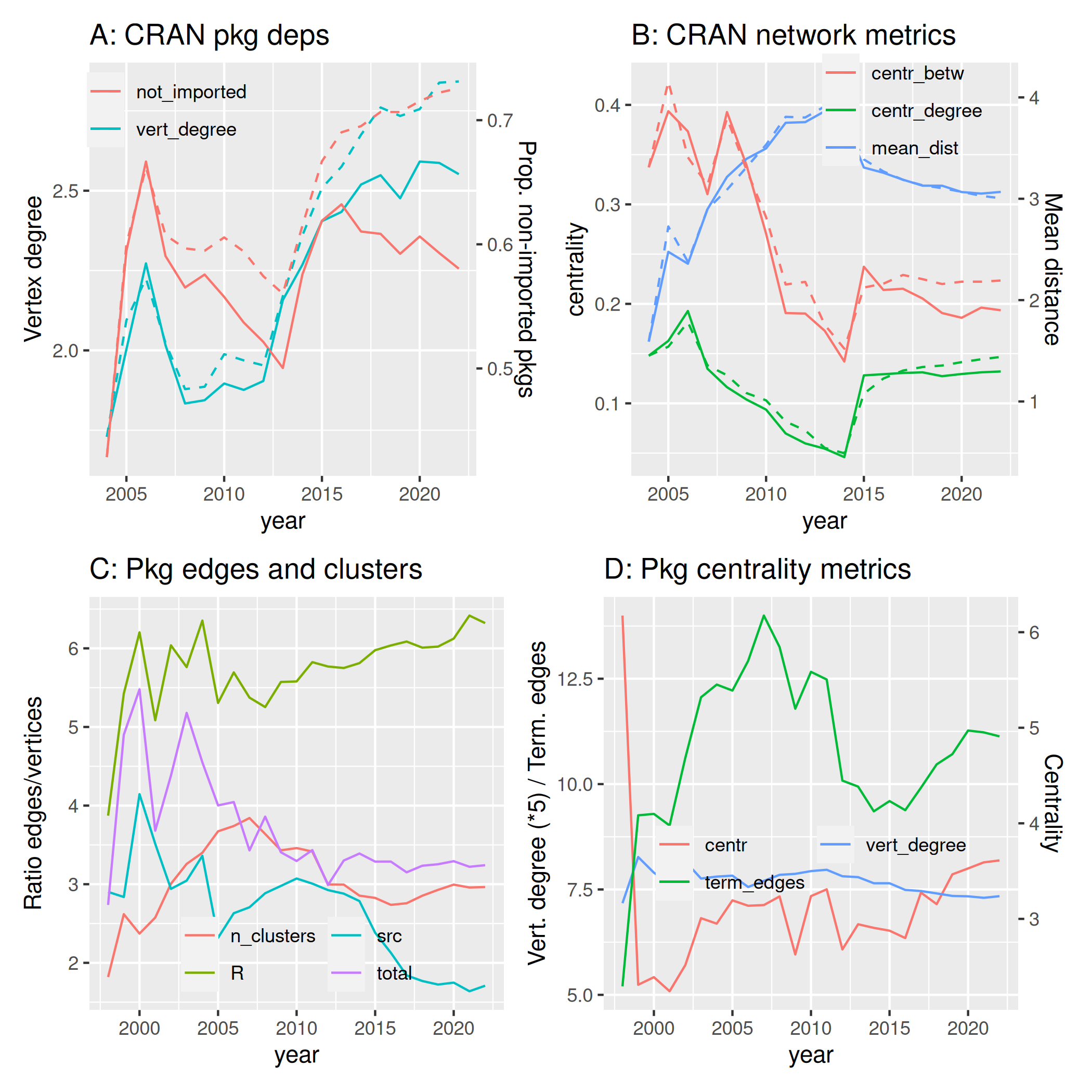
Such an increase in average numbers of imports increases the overall connectivity of the dependency network. Fig. 8B showing concomitant decreases in both centrality metrics over time. Average distances between each pair of packages in the network increased notably up to around 2013, after which time they have decreased. Since numbers of terminal vertices have remained generally stable, while centrality has decreased, the initial increase in mean distance likely reflects terminal vertices becoming further away. This may reflect the network evolving a number of distinct centres. The more recent decrease in mean distance may then reflect an equivalent centralisation of the dependency network.
The lower two panels of Fig. 8 depict the evolution of function call
networks within individual packages. Fig. 8C shows the ratio of numbers
of edges to numbers of vertices, with higher values indicating more
densely connected networks. Since around 2005, network connections
within R functions, whether exported or not, have remained largely
constant, with each function being called by around 5-6 other functions.
Connections between functions in /src directories have in
contrast decreased considerably, with each /src function
(or object) now being “called” (or referenced, inherited, or any other
method) by just over one other function. The “total” line in Fig. 8C
reveals that ratios of edges to vertices in the full function call
network extending between all directories (including /inst)
have progressively declined throughout the history of CRAN. Prior to
2005, most functions (or objects) were called or otherwise referenced at
least 4 times within a package, decreasing to just over 3 calls or
references in recent years. The final line in Fig. 8C, “n_clusters”,
reveals that functions (or objects) within packages cluster within on
average around three main groups.
The final panel (Fig. 8D) shows average centrality metrics from function call networks, which is stable except for numbers of terminal edges (in that context, meaning numbers of functions which call no other functions), which decreased since around 2005 from over 13 per package to under 10 in 2015, before more recently increasing once again.
Sequential Releases
Analyses of sequential releases can only meaningfully be applied to
the function call networks of Figs. 8C-D, and so Fig. 9 depicts
equivalent values only for those two panels. Fig. 9A reveals that
function call networks tend to become more densely connected as packages
mature, and more so in /src than in /R
directories. The aggregate increase contrasts with the equivalent and
generally decreasing average tendency over time of Fig. 8C. This
contrast can again be explained by the fact that most packages only have
one or two releases, and so packages on CRAN have on average become less
internally connected over time as recently-released packages have
increasingly dominated. The decrease in package connectivity over one
year of Fig. 8C corresponds to an equivalent increase in Fig. 9A after
224 releases, indicating that decreases in internal connectivity through
increasing dominance of recently-released packages far outweighs
compensatory decreases through packages maturing.
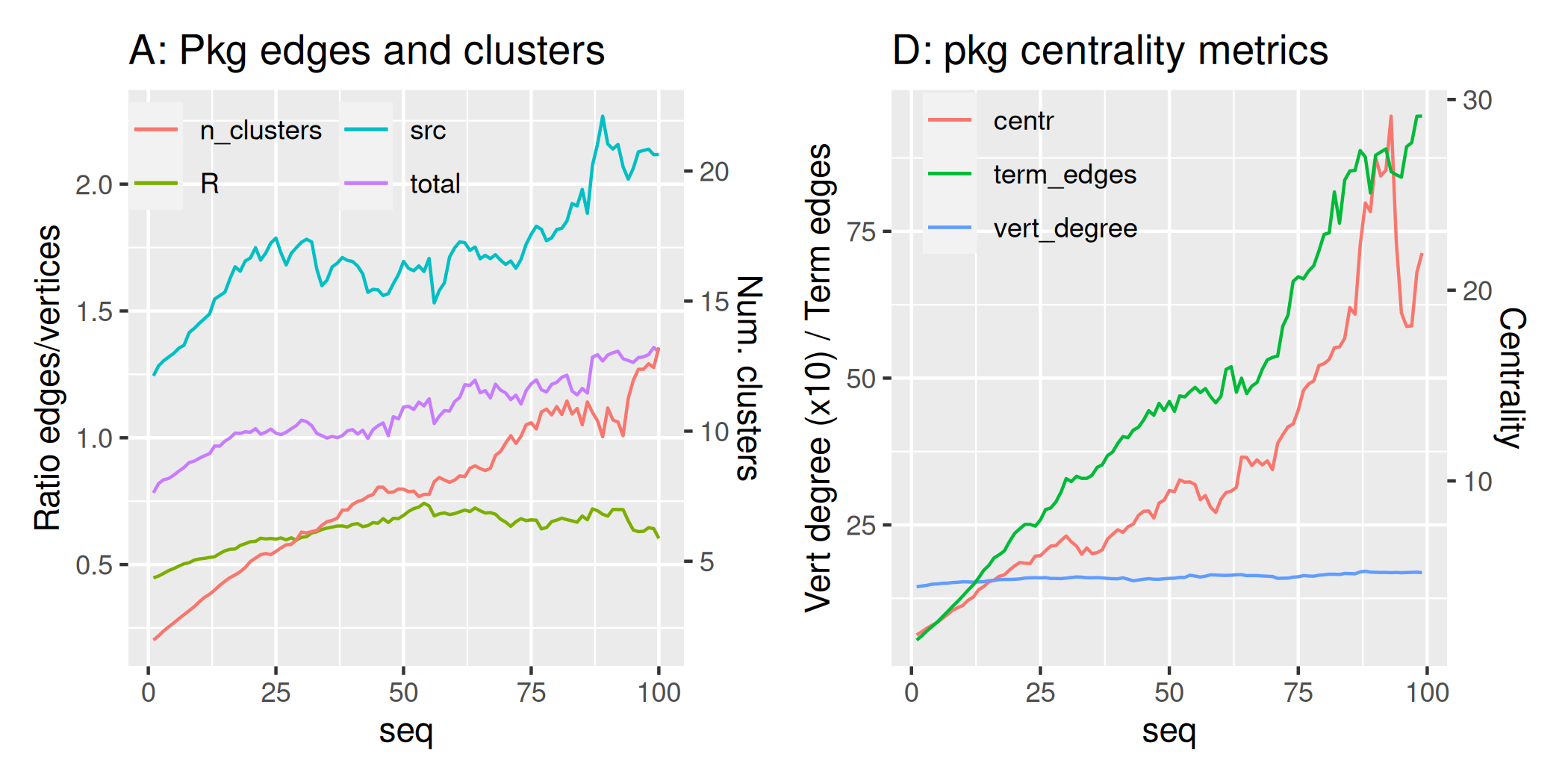
Finally, centrality metrics change dramatically as packages mature (Fig. 9B), in contrast to the annual changes of Fig. 8D. Packages develop greater numbers of terminal edges, yet retain almost identical vertex degrees through becoming more centralised as they develop. One way such an effect could be achieved would be through transforming a package from having several distinct clusters of functions, each internally highly connected yet only loosely coupled to other clusters, towards having fewer numbers of more highly centralised clusters.
Code formatting and Documentation
We conclude these results with analyses generated by the internal
Lines-of-Code routines of {pkgstats}, along with static analyses of the
function documentation (.Rd) files. Proportions of blank and comment
lines have remained similar in both /R and
/src directories over time, except for comment lines in
/R code, which have increased since around 2010. This
roughly corresponds to the first release of the {roxygen2}m package
which has done more than any other package to standardise documentation
of R functions. This increase in /R documentation is likely
a direct reflection of the widespread adoption of {roxygen2} as the
documentation standard for R packages.
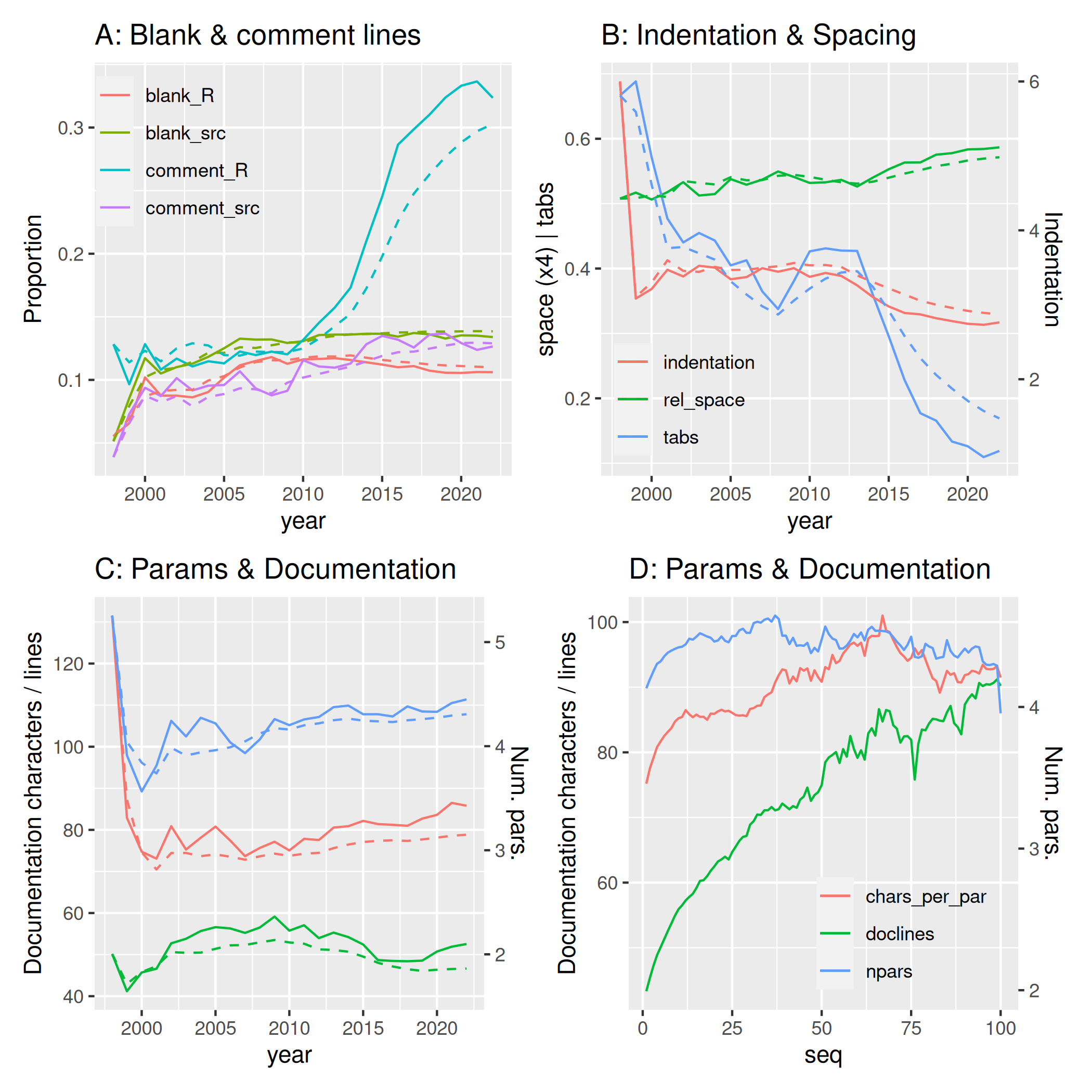
The relative proportion of white space in code lines has increased consistently but slightly over time, amounting to an increase from slightly under 13% to slightly over 14.5%. This value amounts to one additional space for every 67 code characters. The most dramatic development of Fig. 10B is clearly the decrease in the proportion of files with tab-indentation, from well over 60% before the year 2000 to barely over 10% today. Ignoring tabs, code indentation increased until around 2005-2010, remaining constant at 3-3.5 spaces for many years before more recently declining to well under 3 spaces.
Each R function in 1998 had an average of six parameters. This declined rapidly to under four within two years (Fig. 10C). Numbers of parameters have increased since then, and now exceed an average of four parameters per function. Parameter documentation has followed an almost identical trend, increasing from under 70 characters per parameter to 90-100. In contrast, total numbers of documentation lines per function initially increased until around 2010, at almost 60 lines, before decreasing more recently to 50 lines per function or less.
The equivalent results analysed as a function of release sequence rather than year reveal that functions become better documented as packages mature (Fig. 10D), although not through additional documentation of parameters. As with preceding results, the recent decrease in documentation lines per function likely reflects an increasing prevalence of recently released packages which outweighs increases in function documentation as individual packages mature.
Finally, contrasting Figs. 10C and 10D show likely show an increasing dominance of recent packages on numbers of parameters per function. While this number has increased over recent years (Fig. 10C), numbers of parameters also decrease as packages mature, equating to an average of one parameter fewer in all functions after 58 releases. The equivalent annual effect (Fig. 10C) would translate to one additional parameter every 46 years. The average interval between package releases over the duration of CRAN has been 207 days, according to which 58 releases would take 33 years. That comparison suggests that the effects of packages maturing in decreasing average numbers of parameters per function (still) slightly out-paces the effect of increasing average numbers of parameters per function through the increasing dominance of recently released packages.
Discussion
These results reveal a number of metrics which appear to have evolved in one direction when collectively measured across all CRAN packages, yet which tend to evolve in opposing directions within the evolution of individual packages. An example is the metric of “coupling instability” which has increased markedly for all packages since around 2010 (Fig. 6B), yet which decreases in any individual package from near one on first release (due to new packages being unable to be used or depended on by other packages) to near zero after around 100 releases. Additional examples arose in proportions of calls to base R functions, which have collectively decreased over time (Fig. 6A), from over 80 to under 70%, while calls to contributed packages have collectively increased from under 1% to almost 15% in 2022 While individual packages tend to use proportionally fewer calls to base R functions as they mature, they also use proportionally fewer calls to contributed packages, and substitute both of these with increasing proportions of calls to recommended packages (Fig. 7A). Simpler examples also arise in variables like numbers of R functions per file, which have decreased consistently over CRAN as a whole (Fig. 4D), yet which increase progressively as individual packages mature (Fig. 5D).
These general patterns indicate the ubiquity of a dual dynamic between individual packages tending to develop or evolve in one particular direction, yet CRAN as a whole collectively developing in opposing directions due to becoming increasingly dominated by less mature packages in relatively preliminary states of development. It is of course generally not straightforward for many metrics considered here to determine whether an observed trajectory might be a positive development for CRAN as a whole or not. The example of coupling instability nevertheless provides one metric with a clear understanding, and for which high values are generally considered undesirable (Martin 2003). In this context at least, the ongoing development of CRAN is defined by a dynamic balance between the stabilising influence of mature packages, and the converse and potentially destabilising influences of increasing numbers of recently contributed packages.
Even balances between variables like these which are relatively easy to interpret must be considered carefully. For example, the preceding results made several comparisons through quantifying relative rates of change of such opposing tendencies. Direct comparisons presume more recent packages to have equal weight or influence on the overall system dynamic as do more mature packages. It may be more appropriate to implement some form of weighted analyses, for example, through weighting the contributions of individual packages by numbers of dependent packages. This point is considered further in the concluding section below.
The Influence of Code-Hosting Platforms
Many results presented here manifest distinct temporal changes from around the year 2010 onwards, or a year or two after the establishment of online code-hosting platforms such as GitHub, GitLab, and Bitbucket (Source Code Hosting 2022). The synchronous advent of these platforms in Fig. 1B and increases in acknowledged contributors since 2010 in Fig. 1A provides suggestive evidence that the ability to collaboratively develop and disseminate code on these platforms has led to an increase in public acknowledgement of source code contributions. Encouragingly, these increases since around 2012 are roughly linear, and show no sign of slowing down.
GitHub has been the dominant platform by far, generally accounting for close to an order of magnitude more URL entries than equivalent git-based platforms such as Bitbucket and GitLab. The recent decrease of GitHub URLs in the top ten shown in Fig. 2B has been slightly offset by an increase in rOpenSci URLs. rOpenSci provides a peer-review service for R packages, both generally improving code quality and publicising packages to a wider audience than what they might otherwise have reached from authors’ own GitHub profile pages. These increases in both GitHub and rOpenSci URLs reflect increased community engagement in the ongoing development of R packages.
While such increased engagement may generally be viewed as positive, increased public awareness of other peoples code facilitated by code hosting platforms also seems to have produced increased dependence of R packages on other R packages. Coupling instability between packages has increased markedly since 2010 (Fig. 6B). (The less clear patterns of Gini coefficients of equality of dependency networks are discussed further below.)
Several of the network metrics of Fig. 8 also generally reveal abrupt transitions around 2012. The proportion of packages not imported by any others increased very abruptly (Fig. 8A), although this seems to have stabilised more recently, at around 60-70% of all packages. The increase in vertex degree also shown in that panel has nevertheless increased more progressively, only increasing at a slower rate more recently. As mentioned, these increases must mean that each package which is imported by other packages is imported an increasing number of times.
The additional network metrics of Fig. 8B (network centrality, and mean inter-nodal distance) all manifest generally progressive linear trajectories up until around 2013, following which they have largely stabilised. This initial phase prior to that time was marked by decreasing centrality alongside increasing inter-nodal distances, suggestive of a de-centralising network. Against this trajectory, the advent of code hosting platforms has clearly had a stabilising effect in once again “re-centralising” the CRAN dependency network, and decreasing inter-nodal distances.
Quantifying the temporal development of software systems
We calculated two measures of temporal development of software on CRAN. “Snapshot” values considered the collective properties of the system as it existed in each year, including latest versions of all packages regardless of when those packages were last updated. “Annual” values only considered software uploaded in each year. Snapshot values may be generally presumed to reflect exponentially-smoothed versions of annual values, so these two approaches to aggregating annual values ought to qualitatively agree. Nonetheless, some distinct differences appear when comparing these two approaches.
Such differences appear in the annual change of Gini coefficients of Fig. 6C, which presented coefficients both for inequality between numbers of package dependencies, and numbers of individual functions from those dependencies. Calculating annual values only from software uploaded in each year (“annual” values; solid lines in that figure) yielded Gini coefficients which have decreased over the last two decades, while using “snapshot” values produced opposing trajectories of increasing Gini coefficients (dashed lines).
Decan et al. (2019) claimed that Gini
coefficients for all seven package distribution systems they studied had
increased over time. These coefficients measure relative inequality in
the distributions of numbers of package imports, with larger values
reflecting systems with greater disparities between packages in numbers
of imports. While Decan et al. (2019) did
not explicitly describe how they defined their annual figures, all data
were derived from the “meta-platform” libraries.io, which
collates software from several distribution systems and computer
languages. Use of data from this platform would only enable “annual”
rather than “snapshot” values to be calculated.
For discrete, non-negative variables such as counts, Gini coefficients must generally increase with the scale or maximal values of those variables. Thus if average numbers of imported packages (or functions) increases over time, so should Gini coefficients. This suggests that observations of increasing Gini coefficients should be interpreted cautiously, as they may merely reflect uniformly increasing dependence on external packages, while observations of decreasing Gini coefficients, as with our “snapshot” values, may reflect genuine changes. Whatever the underlying cause of these observed differences, they clearly reveal the critical importance of precisely specifying the methods used to aggregate annual values. Whatever the underlying cause of these observed differences, they clearly reveal the critical importance of precisely specifying the methods used to aggregate annual values.
Collective versus individual software evolution
Beyond methods used to aggregate annual values, these results reveal striking contrasts between the collective evolution of CRAN as a unified software ecosystem, and the development trajectories of individual packages. Consider, for example, Fig. 3 showing numbers of files. These manifest clearly increasing trajectories over the lifetimes of individual packages, yet trajectories for CRAN as a whole are far less clear, mixing increases with decreases with other, non-linear patterns. This only clear insight that emerges from the two panels of this figure is that this metric provides direct insight into the evolution of individual packages. Given the foregoing discussions of increasing dominance over time of newer and relatively less mature packages on CRAN, the annual developments of Fig. 3A may indeed reflect nothing more than a confounding of individually-increasing numbers of files in more mature packages mixed with increasing numeric dominance of less mature packages in the system as a whole. Other results such as Fig. 4D (decreasing numbers of functions per file per year) and 5D (increasing numbers of functions per file per release) clearly reflect opposing trajectories, against which any intermediate results such as initially increasing annual numbers of functions followed by subsequent decreases (Fig. 4C) must be presumed to reflect a dynamic balance between the trajectories of individual packages (clear increases in Fig. 5C) with increasing dominance of newer packages.
These and many other aspects of these results clearly indicate that the temporal evolution of collective software systems can only be understood alongside equivalent understanding of the temporal evolution of individual packages. Collective properties alone are inadequate to understand how a software system has actually evolved. Moreover, future work will likely have to consider and contrast schemes for weighting the relative contributions of different packages to the software ecosystem as a whole. The present results applied uniform weights to all packages, regardless of whether an individual package has 100 lines of code and has never been updated or even downloaded, or whether it has thousands of lines of code and orders of magnitude more downloads. Deriving and applying weighting schemes will be an extremely difficult endeavour, especially because there can never be any single, optimal scheme for doing so, and reported results will be intimately dependent on any chosen weighting scheme. We hope that the present work provides a firm empirical basis from which to begin the task of developing such schemes in order to further understanding of the evolution of software ecosystems.
In conclusion, to return to where we started, with the initial consideration of “packages to compute on R packages” (Hornik 2012),
we need better data to do computational statistics on statistical computing solutions: certainly, the CRAN package repository should be an extremely valuable resource for the community, both for gathering and analyzing such data.
This study has demonstrated that the comparably unique nature of CRAN, in being both centralised and archived, does indeed ensure that it represents an extremely valuable resource. We hope that this present study represents an intermediate milestone on the journey first hinted at one decade ago of attempts to delve deeper in to the wealth of data provided by CRAN.